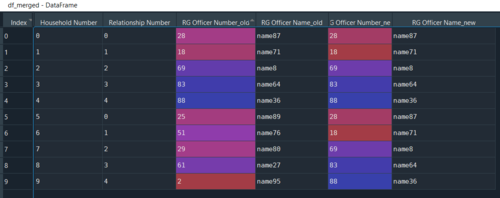
我在 pandas 中有一個(gè)循環(huán),速度非常慢(十多分鐘)。我試圖用矢量化函數(shù)替換它,但不知道該使用什么。有多個(gè)記錄具有不同的家庭號(hào)碼但具有相同的關(guān)系組號(hào)碼,如果記錄的家庭號(hào)碼與關(guān)系組號(hào)碼相同,那么我想將該記錄的官員號(hào)碼和姓名用于具有該關(guān)系組的所有記錄號(hào)碼(包括家庭號(hào)碼不同的情況)。參見(jiàn)下面的代碼: rg['RG Officer Number'] = pd.np.nan rg['RG Officer Name'] = pd.np.nan for index, row in rg.iterrows(): if row['Relationship Group'] == row['Household Number']: mask = rg['Relationship Group'] == row['Relationship Group'] rg.loc[mask, 'RG Officer Number'] = row['Household Primary Officer Number'] rg.loc[mask, 'RG Officer Name'] = row['Household Primary Officer Name'] 我嘗試了以下操作,但出現(xiàn)錯(cuò)誤(無(wú)法使用單個(gè) bool 來(lái)索引 setitem)。我想我完全偏離了軌道。也許這對(duì)于向量化函數(shù)來(lái)說(shuō)是不可能的,但似乎不應(yīng)該如此。 mask = row['Relationship Group'] == row['Household Number'] rg.loc[mask, 'RG Officer Number'] = rg.loc['Household Primary Officer Number']您提供的任何幫助將不勝感激。
用矢量化函數(shù)替換慢速 Pandas 循環(huán)
蠱毒傳說(shuō)
2023-10-26 15:27:13