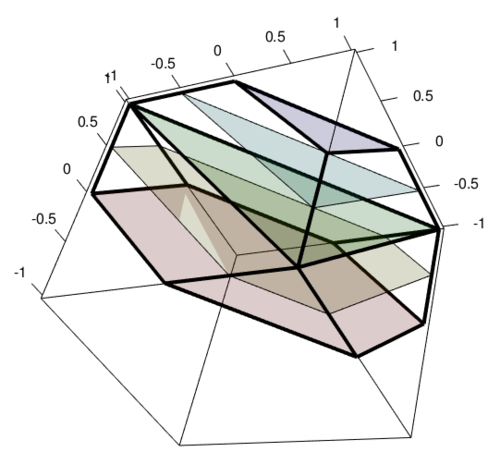
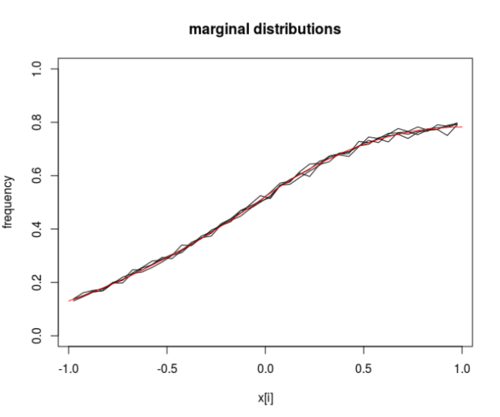
x創(chuàng)建給定值的NumPy 數(shù)組的最佳方法是什么,其size值隨機(jī)(且均勻?)分布在-1和之間1,并且總和也為1?我嘗試2*np.random.rand(size)-1并np.random.uniform(-1,1,size)基于這里的討論,但是如果我采用轉(zhuǎn)換方法,通過之后按它們的總和重新縮放這兩種方法,x/=np.sum(x)這可以確保元素總和為 1,但是:數(shù)組中的某些元素突然變得更大或小于 1 (> 1, < -1),這是不需要的。
值在 -1 到 1 之間并且總和為 1 的隨機(jī) numpy 數(shù)組
慕運(yùn)維8079593
2023-08-03 17:20:15