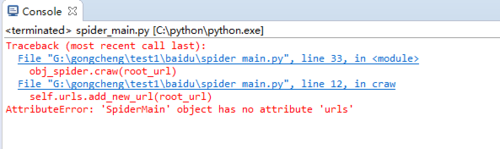
報錯AttributeError: 'SpiderMain' object has no attribute 'urls'
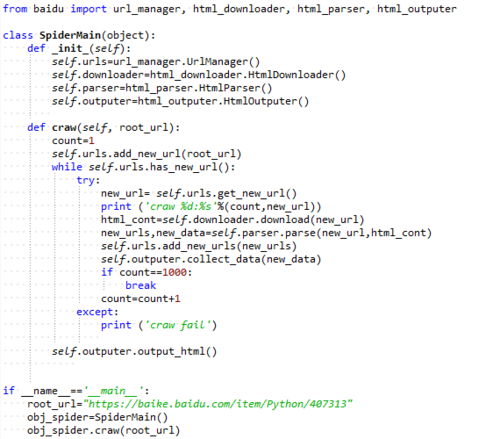
from baidu import url_manager, html_downloader, html_parser, html_outputer
class SpiderMain(object):
? ? def _init_(self):
? ? ? ? self.urls=url_m
anager.UrlManager()
? ? ? ? self.downloader=html_downloader.HtmlDownloader()
? ? ? ? self.parser=html_parser.HtmlParser()
? ? ? ? self.outputer=html_outputer.HtmlOutputer()
? ? ? ??
? ? def craw(self, root_url):
? ? ? ? count=1
? ? ? ? self.urls.add_new_url(root_url)
? ? ? ? while self.urls.has_new_url():
? ? ? ? ? ? try:
? ? ? ? ? ? ? ? new_url= self.urls.get_new_url()
? ? ? ? ? ? ? ? print ('craw %d:%s'%(count,new_url))
? ? ? ? ? ? ? ? html_cont=self.downloader.download(new_url)
? ? ? ? ? ? ? ? new_urls,new_data=self.parser.parse(new_url,html_cont)
? ? ? ? ? ? ? ? self.urls.add_new_urls(new_urls)
? ? ? ? ? ? ? ? self.outputer.collect_data(new_data)
? ? ? ? ? ? ? ? if count==1000:
? ? ? ? ? ? ? ? ? ? break
? ? ? ? ? ? ? ? count=count+1
? ? ? ? ? ? except:
? ? ? ? ? ? ? ? print ('craw fail')
? ? ? ? ? ? ? ??
? ? ? ? self.outputer.output_html()
? ? ? ? ? ??
if __name__=='__main__':
? ? root_url="https://baike.baidu.com/item/Python/407313"
? ? obj_spider=SpiderMain()
? ? obj_spider.craw(root_url)
2020-07-14
我也遇到這個問題了 同問