TypeError: 'NoneType' object is not iterable 怎么解決啊?
#coding:utf-8 from?baike_spider?import?url_manager,?html_downloader,?html_parser,\ ????html_outputer class?SpiderMain(object): ????def?__init__(self):????#這些模塊我們需要在各個(gè)函數(shù)中進(jìn)行初始化 ????????self.urls=url_manager.UrlManager()??#url管理器 ????????self.downloader=html_downloader.HtmlDownloader()?#html下載器 ????????self.parser=html_parser.HtmlParser()??#html解析器 ????????self.outputer=html_outputer.HtmlOutputer()??#輸出器 ???????? ????#爬蟲(chóng)的調(diào)度程序 ????def?craw(self,?root_url): ????????count=1 ????????self.urls.add_new_url(root_url)??#將入口url添加到管理器,這時(shí)url管理器中就有待爬取的url了 ????????while?self.urls.has_new_url():??#循環(huán):判斷url管理器中是否有待爬取的url,即'has_new_url'為True或者False ????????????#try: ????????????new_url=self.urls.get_new_url()?#url管理器中有待爬取的url,通過(guò)get_new_url獲取一個(gè)待爬取的url ????????????print?'craw?%d?:?%s'%(count,new_url)??#打印正在打印第幾個(gè)url ????????????html_cont=self.downloader.download(new_url)?#獲取到一個(gè)待爬取的url后,啟動(dòng)下載器下載這個(gè)頁(yè)面,結(jié)果儲(chǔ)存在html_cont ????????????new_urls,new_data=self.parser.parse(new_url,html_cont)?#24行:下載好的頁(yè)面,調(diào)用parser解析器來(lái)解析這個(gè)頁(yè)面,得到新的url列表(new_urls)和新的數(shù)據(jù)(new_data),解析器傳入兩個(gè)參數(shù),當(dāng)前爬取的url(new_url),以及下載好的頁(yè)面數(shù)據(jù)(html_cont) ????????????self.urls.add_new_urls(new_urls)??#解析得到新的url(new_urls),添加到url管理器 ????????????self.outputer.collect_data(new_data)?#收集數(shù)據(jù)(new_data) ???????????? ????????????if?count==1000: ????????????????break ????????????count+=1 ???????????? ????????????#except:???????????#遇到異常情況的處理(某個(gè)url無(wú)法訪問(wèn) ????????????????#print?'craw?failed' ???????????????? ????????self.outputer.output_html() ???? ???? #首先,編寫(xiě)main函數(shù) if?__name__=='__main__': ????root_url='http://baike.baidu.com/item/Python'??#設(shè)置入口url ????obj_spider=SpiderMain()???#創(chuàng)建實(shí)例,SpiderMain為類 ????obj_spider.craw(root_url)?#調(diào)用spider的craw方法,來(lái)啟動(dòng)爬蟲(chóng)
#coding:utf-8 #在每個(gè)模塊中創(chuàng)建主程序所需的class class?UrlManager(object): ????def?__init__(self): ????????self.new_urls=set()??#新的和已經(jīng)爬取過(guò)的url全部?jī)?chǔ)存在?set()中 ????????self.old_urls=set() ???? ????#向管理器中添加一個(gè)新的url ????def?add_new_url(self,url):??#(利用這個(gè)方法.使self.new_urls中增加一個(gè)新的待爬取url) ????????if?url?is?None: ????????????return??#不進(jìn)行添加 ????????if?url?not?in?self.new_urls?and?url?not?in?self.old_urls: ????????????self.new_urls.add(url) ???? ????#向管理器中添加批量新的url ????def?add_new_urls(self,urls):???#new_urls為網(wǎng)頁(yè)解析器解析得到的新的待爬取url列表 ????????if?urls?is?None?or?len(urls)==0:??#如果這個(gè)urls列表長(zhǎng)度為空或者為None ????????????return??#不進(jìn)行添加 ????????for?url?in?urls: ????????????self.add_new_url(url)???##注意一下 ???? ????#判斷管理器中是否有待爬取的url ????def?has_new_url(self):????????#has_new_url?用于spider_main中while語(yǔ)句的判斷 ????????return?len(self.new_urls)?!=0???#如果長(zhǎng)度不為0,就有待爬取的url ???????????? ???????? ????#從url管理器中獲取一個(gè)新的待爬取的url ????def?get_new_url(self): ????????new_url=self.new_urls.pop()??#從列表中獲取一個(gè)url,并移除這個(gè)url ????????self.old_urls.add(new_url) ????????return?new_url??#返回的new_url用于spider_main中的get_new_url
#coding:utf-8 import?urllib2 #在每個(gè)模塊中創(chuàng)建主程序所需的class class?HtmlDownloader(object): ???? ???? ????def?download(self,url): ????????if?url?is?None: ????????????return?None ????????response=urllib2.urlopen(url)??#爬百度百科用的的為最簡(jiǎn)單的urllib2代碼,沒(méi)有cookie和代理的考慮 ????????if?response.getcode()?!=200: ????????????return?None ????????print?response.read()
#coding:utf-8
from?bs4?import?BeautifulSoup
import?re
import?urlparse
#在每個(gè)模塊中創(chuàng)建主程序所需的class
class?HtmlParser(object):
????
????
????def?_get_new_urls(self,?page_url,?soup):???#page_url是什么??page_url是主程序spider_main中給定的參數(shù)new_url.
????????new_urls=set()
????????#/item/123
????????links=soup.find_all('a',href=re.compile(r'/item/'))??#compile(r"/item/\d+\\"))??#'\\',前一個(gè)\用來(lái)取消后一個(gè)\的轉(zhuǎn)義功能
????????for?link?in?links:
????????????new_url=link['href']
????????????new_full_url=urlparse.urljoin(page_url,new_url)?#將new_url按照page_url的格式,生成一個(gè)全新的url
????????????new_urls.add(new_full_url)
????????return?new_urls
????
????def?_get_new_data(self,?page_url,?soup):
????????res_data={}
????????
????????#url
????????res_data['url']=page_url
????????
????????#<dd?class="lemmaWgt-lemmaTitle-title">??<h1>Python</h1>
????????title_node=soup.find('dd',class_="lemmaWgt-lemmaTitle-title").find('h1')
????????res_data['title']=title_node.get_text()??#原先寫(xiě)錯(cuò)成get_txt()
????????#<div?class="lemma-summary"?label-module="lemmaSummary">
????????summary_node=soup.find('div',class_="lemma-summary")
????????res_data['summary']=summary_node.get_text()
????????
????????return?res_data
????
????
????def?parse(self,page_url,html_cont):???#其中,(page_url,html_cont)就是?spider_main中第24行輸入的參數(shù)?(new_url,html_cont)
????????if?page_url?is?None?or?html_cont?is?None:
????????????return
????????soup=BeautifulSoup(html_cont,'html.parser',from_encoding='utf-8')
????????new_urls=self._get_new_urls(page_url,soup)??#創(chuàng)建self._get_new_urls本地方法,這個(gè)方法主要是為了find_all所有相關(guān)網(wǎng)頁(yè)url,并補(bǔ)全url,輸出到new_urls這個(gè)列表當(dāng)中,給spider_main使用
????????new_data=self._get_new_data(page_url,soup)??#創(chuàng)建self._get_new_data
????????return?new_urls,new_data#coding:utf-8
#在每個(gè)模塊中創(chuàng)建主程序所需的class
class?HtmlOutputer(object):
????def?__init__(self):
????????self.datas=[]
????
????def?collect_data(self,data):
????????if?data?is?None:
????????????return
????????self.datas.append(data)
????
????def?output_html(self,data):
????????fout=open('output.html','w')
????????
????????fout.write("<html>")
????????fout.write("<body>")
????????fout.write("<table>")
????????
????????#ascii
????????for?data?in?self.datas:
????????????fout.write("<tr>")
????????????fout.write("<td>%s</td>"%?data['url'])
????????????fout.write("<td>%s</td>"%?data['title'].encode('utf-8'))
????????????fout.write("<td>%s</td>"%?data['summary'].encode('utf-8'))
????????????fout.write("</tr>")
????????
????????fout.write("</table>")
????????fout.write("</body>")
????????fout.write("</html>")
????????
????????
????????fout.close()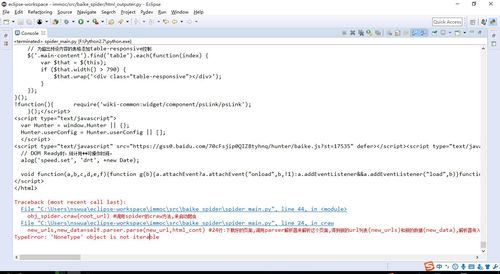
按照評(píng)論分享的代碼重新改了幾個(gè)地方,但依然出現(xiàn)這個(gè)錯(cuò)誤.不知道錯(cuò)在哪里了,代碼以上.
2018-01-04
頁(yè)面 ?html_downloader.py
15行 ??print?response.read() ? 更改為 ?return?response.read()